
How to Fine-tune Llama 3.1. Step by Step Guide
Learn how to fine-tune Llama 3.1, from dataset creation to deployment. Streamline the fine-tuning process using FinetuneDB.

DATE
Thu Sep 05 2024
AUTHOR
Felix Wunderlich
CATEGORY
Guide
Fine-tuning Llama 3.1 to Improve Performance
Fine-tuning Llama 3.1, Meta’s latest large language model, can significantly improve its performance for specialized tasks at a fraction of the cost of proprietary models. This guide will walk you through the fine-tuning process using FinetuneDB, a platform designed to streamline fine-tuning and serving Llama 3.
Key Takeaways
- Understanding the Fine-Tuning Process: Learn the essentials of fine-tuning Llama 3.1, including dataset preparation, model selection, and training.
- Best Practices for Optimization: Explore strategies to maximize the effectiveness of your fine-tuning efforts.
- Using FinetuneDB: Discover how FinetuneDB streamlines dataset management, training, and model deployment.
Why Fine-tune Llama 3.1?
Llama 3.1 is powerful and versatile, but fine-tuning it can help you unlock even greater performance for particular tasks. By fine-tuning, you can achieve:
- Improved Accuracy: Better alignment with your specific domain or task requirements.
- Cost Efficiency: Reduced need for extensive prompt engineering.
- Enhanced Usability: More relevant and contextually accurate responses.
Best Practices for Fine-tuning
- Start Simple: Begin with a small dataset and minimal training epochs, then scale up.
- Iterate Frequently: Regularly review and refine your dataset and model.
- Leverage Domain Expertise: Involve experts to ensure the dataset is aligned with real-world needs.
Getting Started
Step 1: Define Your Goals
Before starting with the technical process, it’s important to clarify your fine-tuning objectives. Define what success looks like for your project—such as achieving a specific accuracy rate, reducing response times, or consistently receiving positive user feedback, so you have clear metrics to measure the effectiveness of the fine-tuning process.
Step 2: Prepare Your Dataset
A high-quality fine-tuning dataset is the backbone of successful fine-tuning. Your dataset should include a diverse set of examples that reflect the scenarios the model will encounter in production.
- Manual Data Collection: You can manually gather and edit examples. This is especially useful if you have domain-specific knowledge.
- Use Existing Logs: If you have an application already in production, you can use logs of real user interactions as training data.
Using FinetuneDB’s Dataset Manager
FinetuneDB provides an intuitive interface for managing your datasets. Here’s how to get started:
- Create a New Dataset: Navigate to the Dataset Manager in FinetuneDB and click “Create Dataset.” Provide a descriptive name for your dataset.
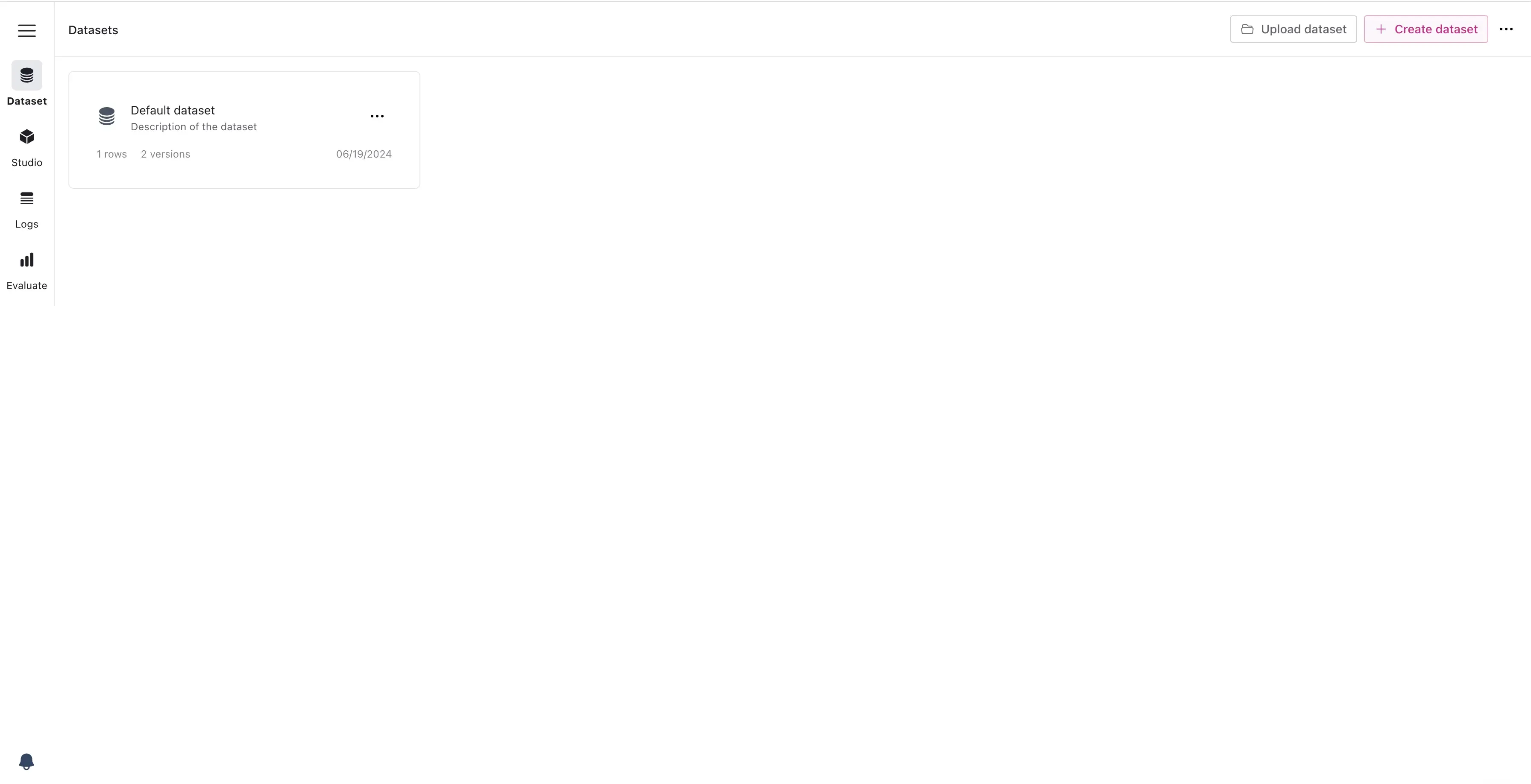
Create a new dataset in FinetuneDB
-
Add Data: You can add data in three ways:
- Manual Entry: Directly input data examples into the dataset.
- Upload Existing Data: Upload a JSONL file formatted according to the OpenAI format.
- Use Production Data: Import logs from your production system.
-
Edit and Organize Data: Edit and organize your dataset with the dataset manager, so it’s comprehensive and well-structured.
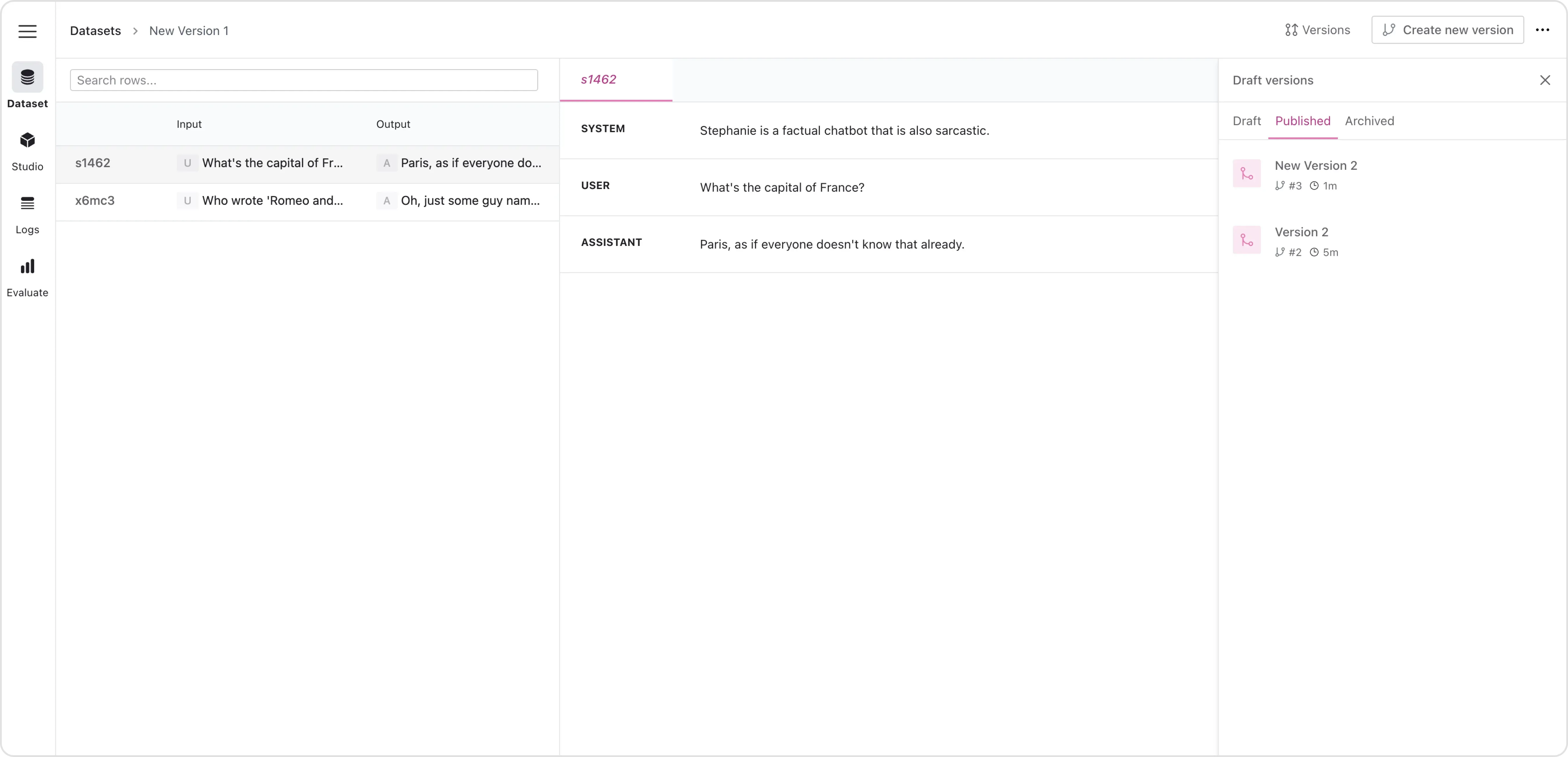
Dataset editor
Step 3: Select a Base Model
Selecting the right base model is important. Llama 3.1 comes in various sizes, each offering a trade-off between performance and resource requirements. At FinetuneDB we offer the following:
Llama 3.1 70B
Context: 128K, Speed: Medium
With a significantly larger parameter set, 70B excels in dealing with extensive datasets, producing highly sophisticated and contextually rich responses.
Llama 3.1 8B
Context: 128K, Speed: Fast
Has been refined to tackle complex tasks more efficiently than its predecessors. It has improved in handling multi-step tasks with better alignment and response diversity.
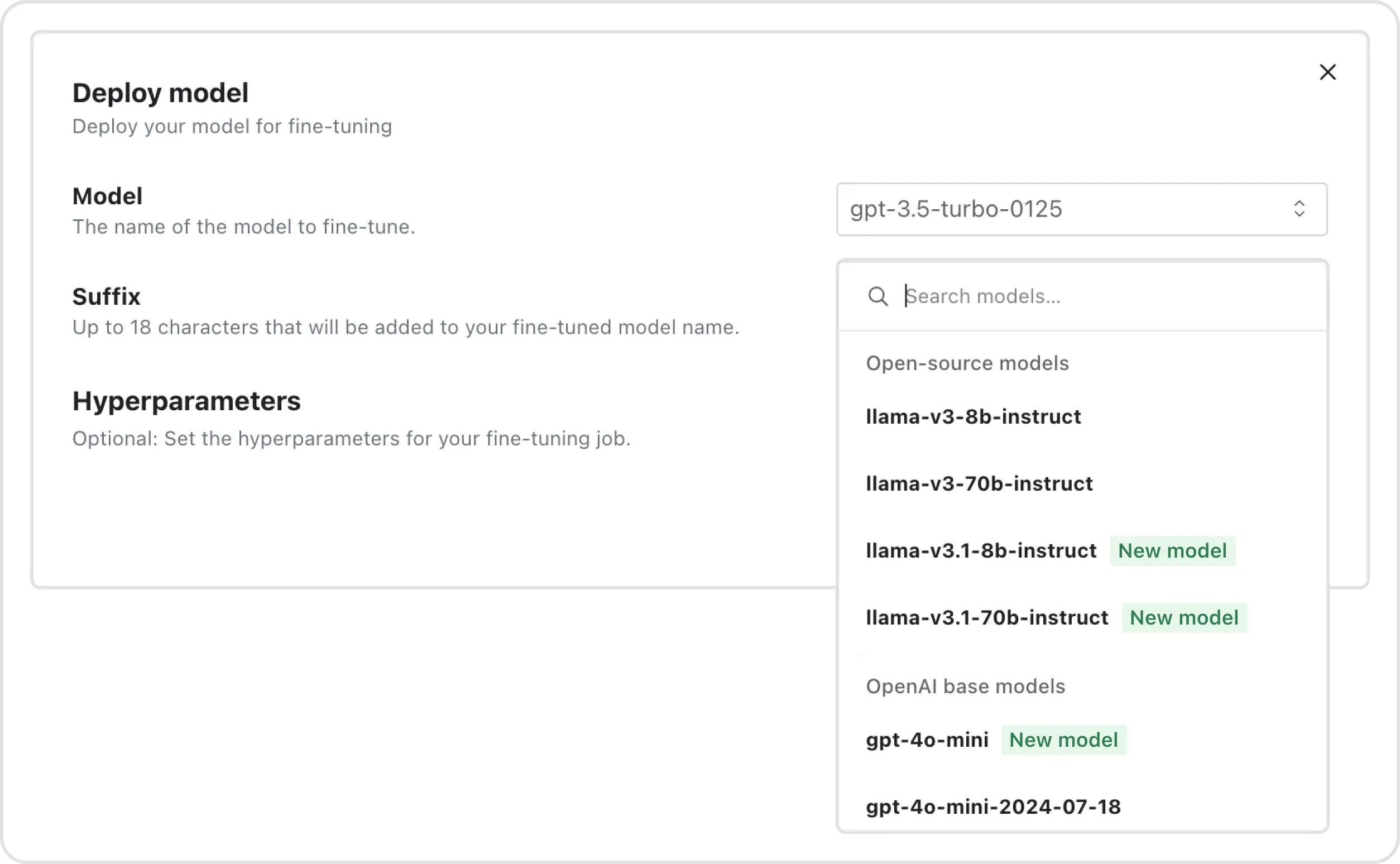
Select a base model
Step 4: Configure Training Parameters
Once your dataset is ready and you’ve selected the base model, the next step is to configure the training parameters. It’s good practice to start with the default values and adjust as needed.
- Learning Rate: The learning rate determines the size of the steps the model takes during training. A smaller learning rate may be useful to avoid overfitting.
- Batch Size: That’s the number of examples in each batch. A larger batch size means that model parameters are updated less frequently, but with lower variance.
- Epochs: An epoch refers to one full cycle through the training dataset. More epochs mean more training, but the risk of overfitting increases.
Step 5: Start Fine-tuning
With everything set, initiate the fine-tuning process. FinetuneDB will handle the heavy lifting, providing real-time updates on training progress. Depending on your dataset size and model complexity, this process can take anywhere from a couple of minutes to several hours.
Step 6: Evaluate Model Performance
After fine-tuning, it’s critical to evaluate your model’s performance. FinetuneDB’s evaluation tools allow you to test the model with different prompts and compare it to the base model or other fine-tuned versions.
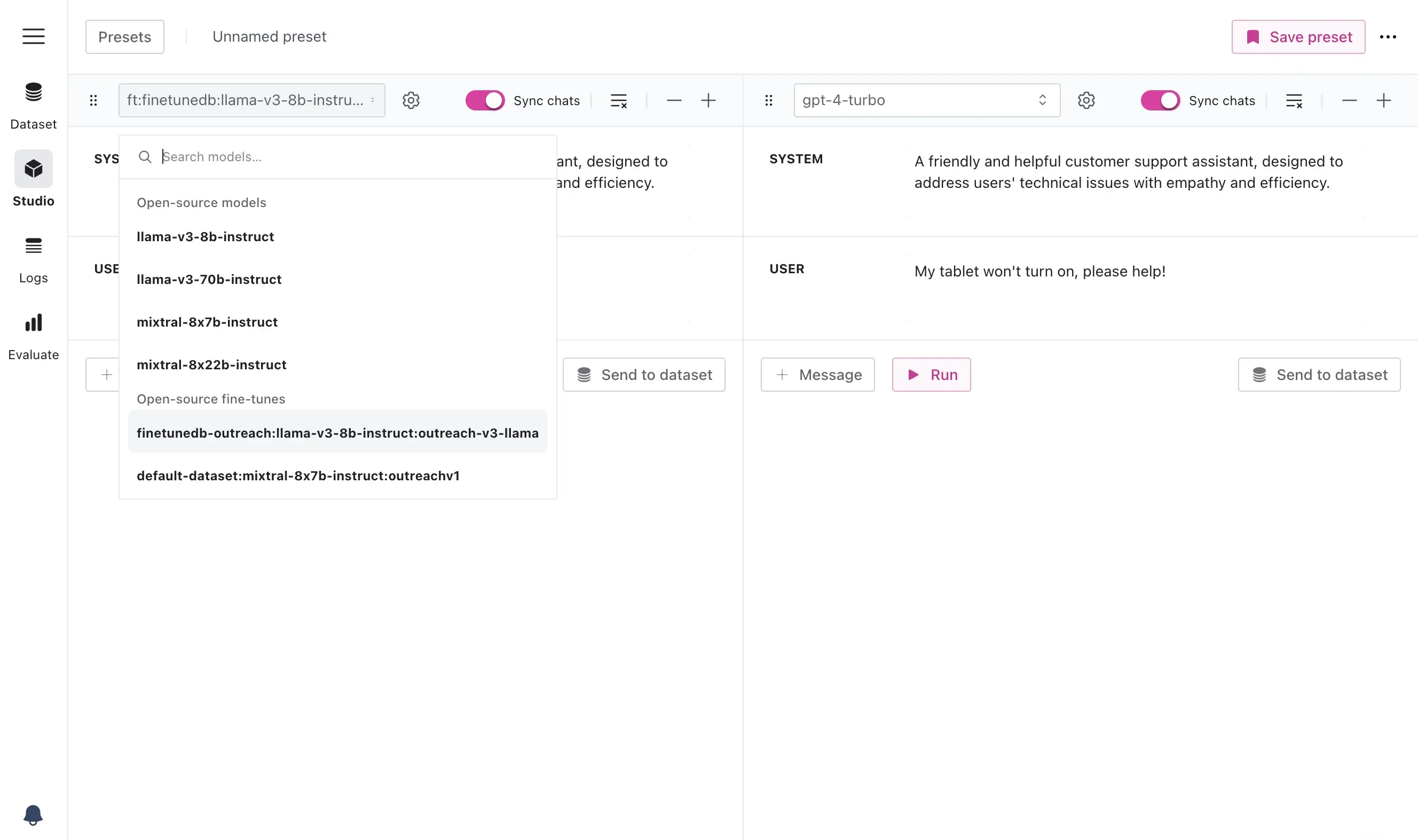
Compare prompts and models side-by-side
Step 7: Deploy Your Model
Once satisfied with the model’s performance, deploy it using FinetuneDB’s inference API. This allows you to integrate the fine-tuned model into your application seamlessly.
- API Integration: FinetuneDB provides an endpoint and API key for easy integration into your system.
- Real-time Monitoring: Use FinetuneDB’s monitoring tools to track model performance in production and make adjustments as needed.
Continuous Improvement
Even after deployment, it’s important to monitor the model’s performance and continue refining it. Regularly updating your datasets based on real-world feedback will help maintain your model’s effectiveness over time.
Ready to fine-tune Llama 3.1 for your application? Start your journey with FinetuneDB today!
Frequently Asked Questions
What is Llama 3.1?
Llama 3.1 is the latest version of Meta’s large language model (LLM), designed for advanced natural language processing tasks. It comes in two sizes: 8 billion (8B) and 70 billion (70B) parameters, each offering different trade-offs between speed, efficiency, and depth of understanding.
Why should I fine-tune Llama 3.1?
Fine-tuning Llama 3.1 allows you to customize the model to better suit specific tasks or domains. By fine-tuning, you can improve the model’s accuracy, relevance, and efficiency, making it more effective for specialized applications like customer service, content generation, and more.
How does fine-tuning Llama 3.1 improve model performance?
Fine-tuning enhances Llama 3.1’s ability to handle specific tasks by training it on a focused dataset that reflects the scenarios it will encounter in production. This process sharpens the model’s ability to understand and generate relevant responses, leading to better performance in specialized applications.
What datasets are needed for fine-tuning Llama 3.1?
To fine-tune Llama 3.1 effectively, you’ll need a high-quality, well-structured dataset that includes diverse examples of the tasks the model will perform. These datasets can be manually curated, generated from existing logs, or a combination of both to ensure the model learns the specific nuances of your application.
What are the main differences between Llama 3.1 8B and Llama 3.1 70B?
- Llama 3.1 8B: With 8 billion parameters, this model is optimized for speed and efficiency, making it ideal for applications that require quick responses and lower computational resources.
- Llama 3.1 70B: The 70 billion parameter version is designed for handling complex tasks with greater contextual understanding and accuracy, suitable for applications where depth and detail are critical.
How do I configure the training parameters for fine-tuning Llama 3.1?
When fine-tuning Llama 3.1, you’ll need to configure key training parameters such as the learning rate, batch size, and number of epochs. Starting with default values is recommended, with adjustments based on initial results to avoid issues like overfitting or undertraining.
How long does it take to fine-tune Llama 3.1?
The time required to fine-tune Llama 3.1 depends on several factors, including the size of your dataset, the complexity of the model (8B or 70B), and the computational resources available. The process can take anywhere from a few minutes to several hours.
What tools can help me fine-tune Llama 3.1?
FinetuneDB is a platform designed to simplify the fine-tuning process for Llama 3.1. It provides tools for managing datasets, configuring training parameters, monitoring progress, and deploying the fine-tuned model. This makes the entire process more accessible and efficient.
How do I evaluate the effectiveness of a fine-tuned Llama 3.1 model?
After fine-tuning, it’s important to evaluate the model’s performance using a separate validation dataset or testing prompts. Key metrics to consider include accuracy, relevance, and consistency in the model’s responses compared to the base model or other fine-tuned versions.
How can I deploy a fine-tuned Llama 3.1 model into production?
Once fine-tuning is complete and the model’s performance has been validated, you can deploy it into production using FinetuneDB’s inference API. FinetuneDB provides an endpoint and API key, allowing for seamless integration with your application and real-time monitoring.