
How to Fine-tune Open-source Large Language Models
Learn how to fine-tune open-source LLMs to get cost-effective, high-performance models. Create fine-tuning datasets, and follow steps to fine-tune and deploy models via an inference API using FinetuneDB.

DATE
Mon Jul 22 2024
AUTHOR
Felix Wunderlich
CATEGORY
Guide
Fine-tuning Open-Source Models
Fine-tuning open-source large language models (LLMs) can greatly improve their performance for specific tasks while reducing costs. This guide covers creating fine-tuning datasets, and the process of fine-tuning and serving models using the FinetuneDB platform.
Key Takeaways
- Understanding Fine-Tuning Datasets: Learn what fine-tuning datasets are and why high-quality, diverse datasets are crucial for effective model performance.
- Creating Datasets: Discover how to use FinetuneDB’s tools to build and manage your datasets, including manual entry, uploading existing data, and leveraging production logs.
- Open-Source Fine-Tuning Process: Follow detailed steps to fine-tune LLMs for specific tasks, including selecting a base model and configuring training parameters.
- Deploying Fine-Tuned Models: Learn how to deploy your fine-tuned models via FinetuneDB’s inference API for production use.
Overview of Fine-tuning Datasets
Fine-tuning datasets are curated collections of examples used to improve the performance of large language models (LLMs) on specific tasks. These datasets ensure that models can understand and respond accurately to particular scenarios, making them more effective for specialized applications. High-quality, diverse datasets are essential as they provide the relevant contexts and examples needed for the model to learn and adapt.
Quality Over Quantity:
The relevance and quality of the data are more crucial than the quantity. High-quality data ensures the model has a clear understanding of the tasks, similar to a student learning better from a well-organized textbook.
Diverse Datasets:
A diverse dataset helps the model respond accurately across various scenarios. Different team members, such as domain experts, contribute to creating a well-rounded dataset.
Example Dataset Entry:
system
A friendly and helpful customer support assistant, designed to address users’ technical issues with empathy and efficiency.
user
My laptop battery isn’t holding a charge anymore.
assistant
I’m sorry to hear that your battery isn’t working as expected. Can you tell me the make and model of your laptop so I can assist you further?
This example helps the LLM understands the context and responds in the tone of voice and way you want the model to behave.
Creating Fine-tuning Datasets with FinetuneDB
Define the Goals:
Start by setting clear objectives for your fine-tuned model. For our electronics industry customer service example, the goal would be to improve response accuracy and customer satisfaction.
Collect and Organize Data:
Gather relevant examples that reflect real-world applications. Make sure your data is high-quality and well-organized, matching the contexts your model will need to excel in.
Use the FinetuneDB Dataset Manager:
Continuing with our customer service example, let’s walk through how the FinetuneDB dataset manager streamlines the process of creating fine-tuning datasets.
- Go to the FinetuneDB platform and open the Dataset Manager.
- Click on “Create Dataset” and provide a meaningful name and description.
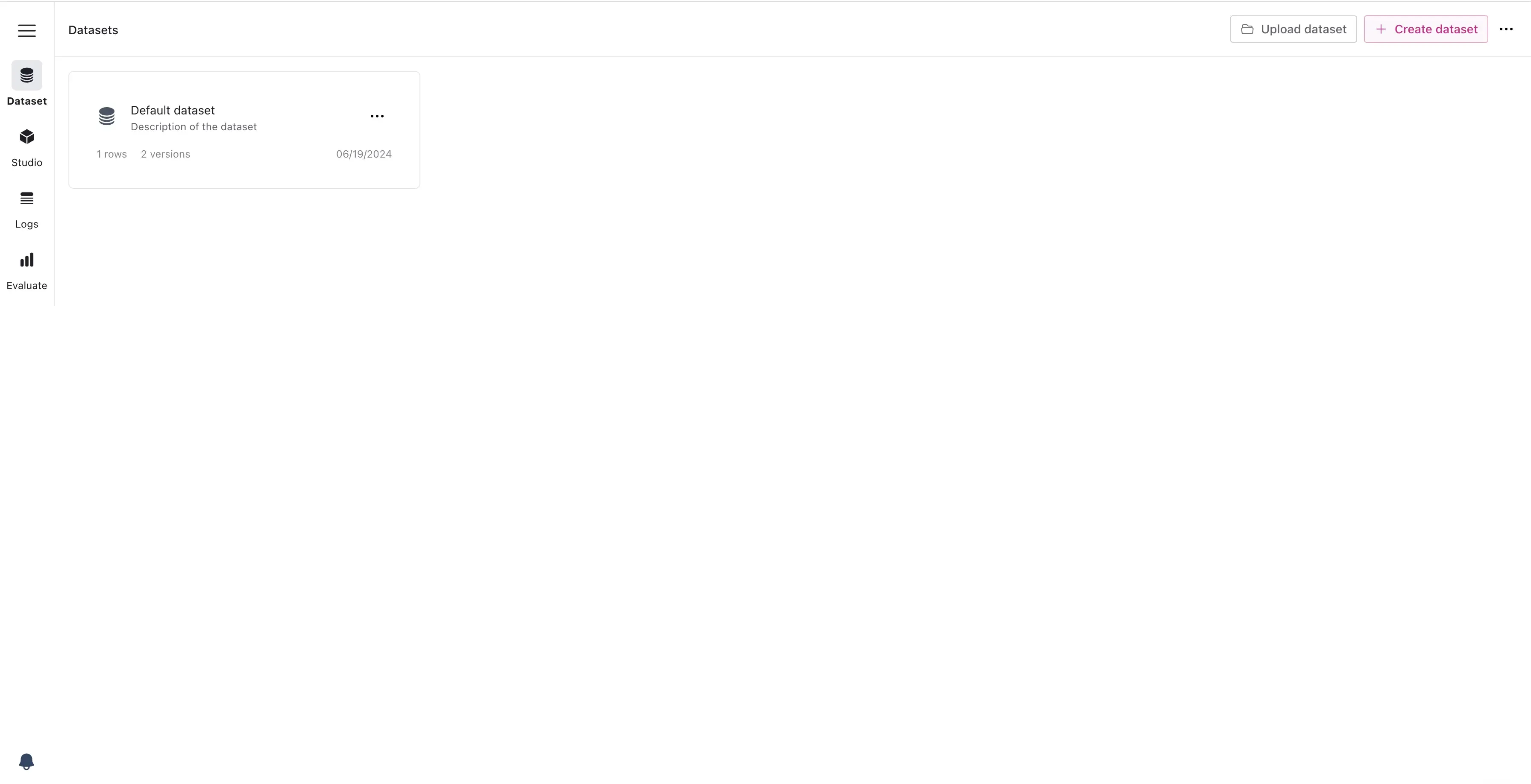
New Dataset
Adding Data:
There are three ways to add data to the dataset manager.
- Manual Entry: Add data entries directly into the dataset manager. For instance, type in the system, customer inquiry, and expected model output as shown in the example.
- Uploading Data: Upload an existing dataset in JSONL format. Each line should be a dataset entry, similar to the example provided and according to the OpenAI format.
- Use Production Data: If you already have an LLM in production, you can use existing production logs to build your dataset.
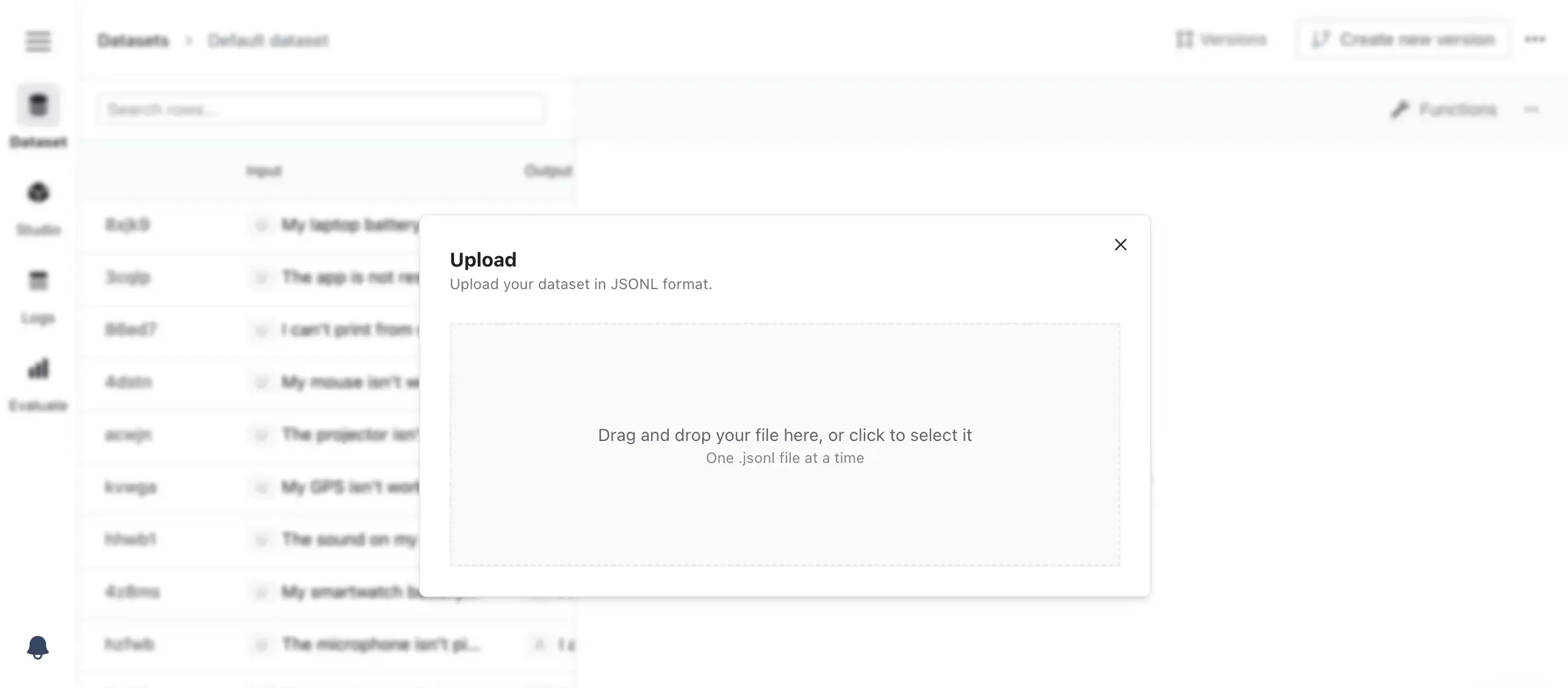
Upload Dataset
Editing the Dataset:
Once you added first data to the dataset manager you will likely need to adjust it together with other contributors or team members. Our editor enables you to easily do so.
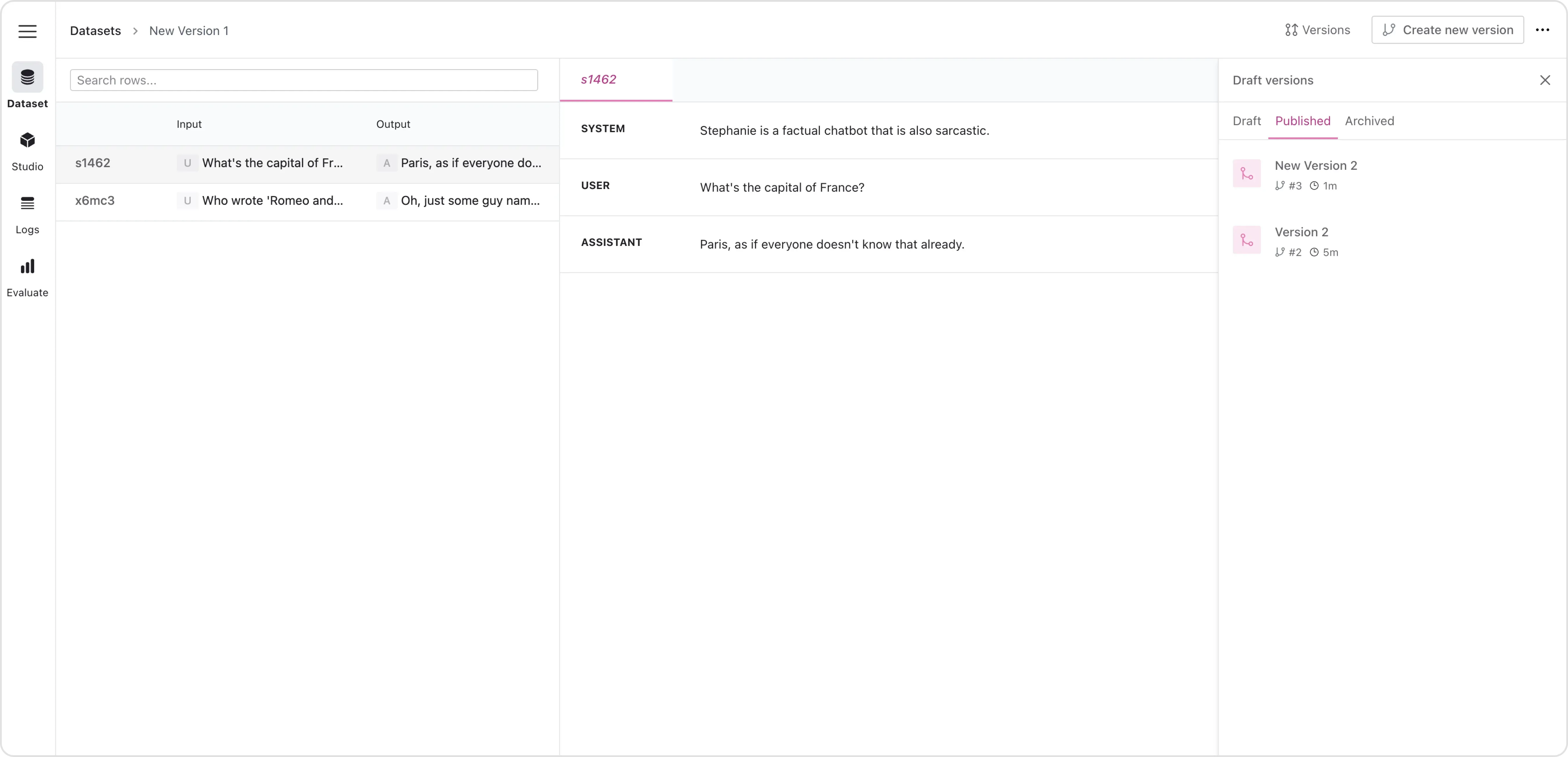
Dataset Editor
-
Collaborating: Invite domain experts, such as customer service representatives, to contribute to the dataset. Assign roles and permissions to manage access effectively.
-
Branching: Suppose a team member suggests a new approach to handling battery-related inquiries. They can create a new version of the dataset, add their suggested responses, and test this new version without affecting the original dataset.
-
Merging: If the new approach is reviewed and approved, the changes can be merged into the main dataset. This allows for continuous improvement and experimentation.
-
Rolling Back: If the new approach is not effective, you can easily roll back to a previous version, ensuring no data is lost and maintaining dataset integrity.
-
Function Calling: Suppose you need to include real-time product availability in responses. Use the Visual Function Calling Editor to add a function that queries an external API for stock information. This enriches the dataset with dynamic, up-to-date information.
For a full feature overview, please visit our documentation.
Once the dataset is curated and a first version is done, the next step is using the dataset to fine-tune a model.
Fine-Tuning Open-source Models with FinetuneDB
Selecting the Training Dataset
Select the dataset you created and initiate the fine-tuning process by clicking “Fine-tuning model”. FinetuneDB’s handles the fine-tuning process and provides real-time updates on the training progress.
Selecting a Base Model
Choose an appropriate open-source model that is pretrained on a large corpus of data. Models like Llama-8b and Mixtral-8x7b-instruct provide a strong foundation for customization. For our customer service use case, selecting Llama-8b ensures robust natural language understanding capabilities necessary for accurate customer interactions.
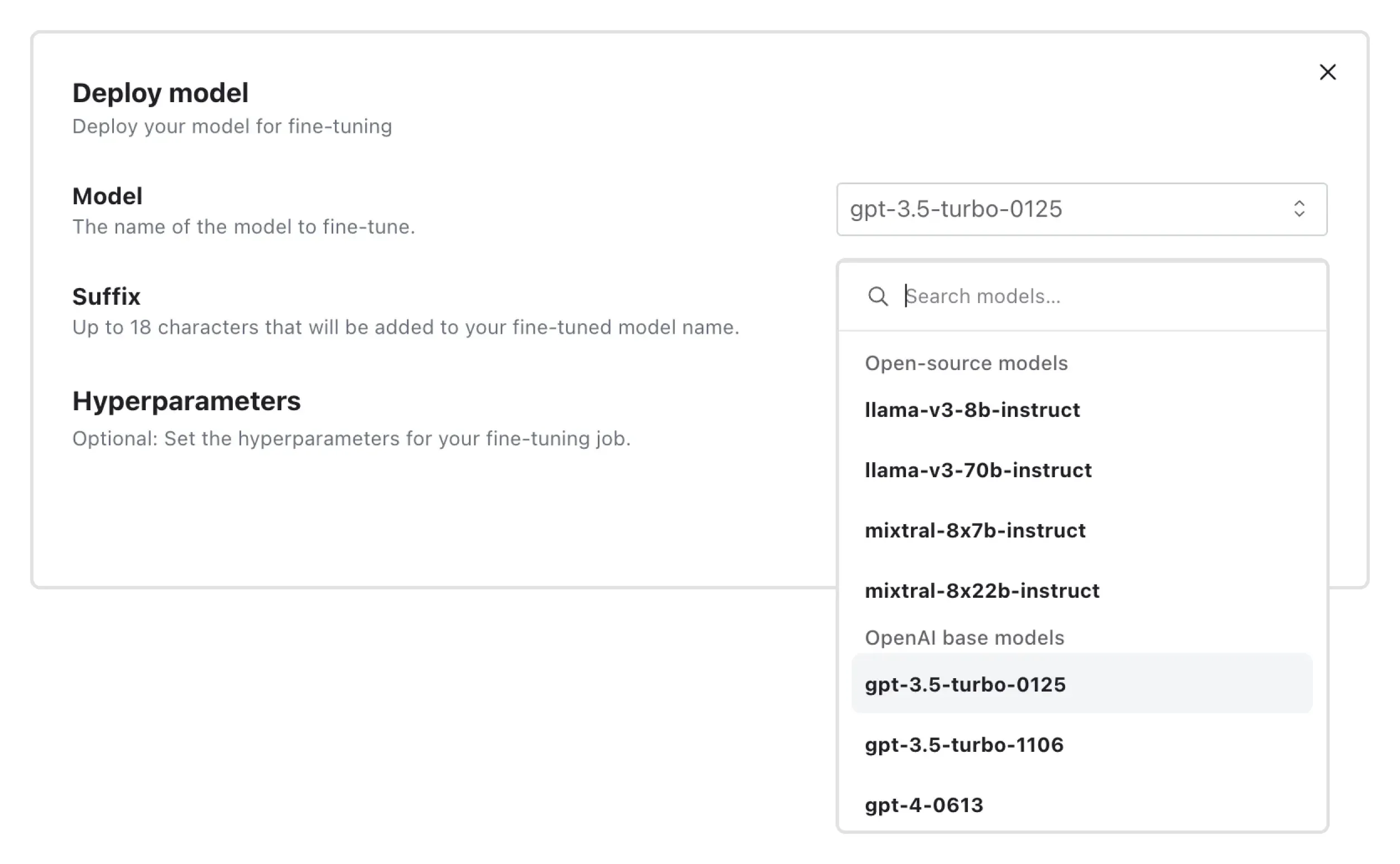
Select Open-Source Model
Training Parameters and Fine-tuning
Adjust key training parameters like learning rate, batch size, and number of epochs to tailor the fine-tuning process. Auto settings work well as a baseline, but can be adjusted if fine-tuning outcomes are not as expected. Once all parameters are set, you can initiate the training with Llama-8b and the customer service dataset. You can monitor the process through FinetuneDB’s real-time updates.
Once training is finished, you optain a fine-tuned model with improved capabilities.
Post Fine-tuning
Evaluating Model Performance
After training, the next step is to thoroughly test the fine-tuned model with new customer inquiries to verify its ability to provide accurate and helpful responses. You can use our Studio environment to test different prompts and compare models side by side.
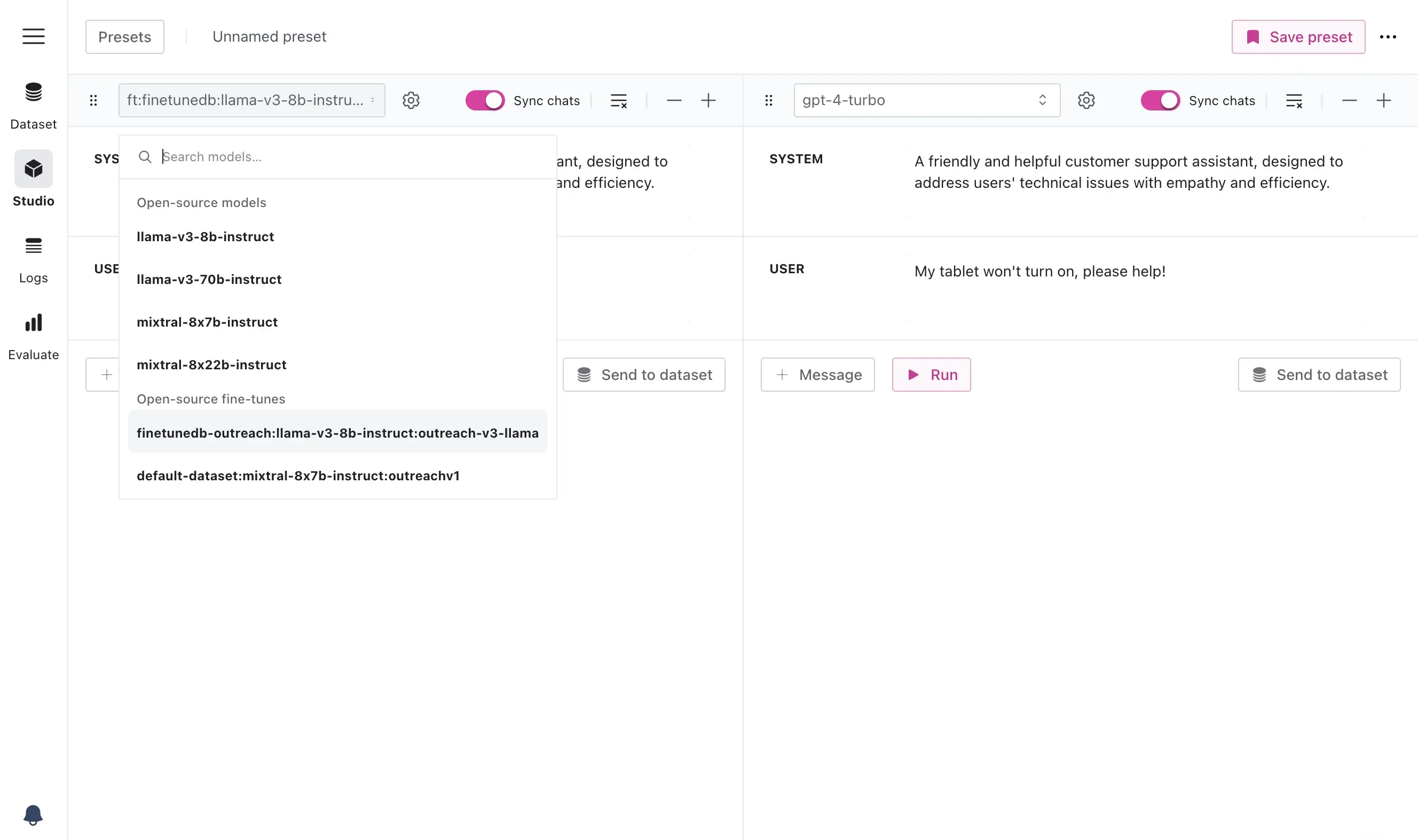
Compare Prompts and Models Side-by-Side
Evaluations are key for reliable model performance. Learn more about Evaluations here: How to Evaluate LLM Outputs
Deploy Fine-tuned Model via Inference API
Once you have evaluated the model’s performance and are confident in its capabilities, the next step is to deploy the fine-tuned model. Deploying your fine-tuned model with FinetuneDB is straightforward and similar to using OpenAI’s API. Read more about this in our documentation.
- Get Your API Key and Endpoint: After fine-tuning, you’ll receive an API key and an endpoint URL from FinetuneDB.
- Make a Request: Send a POST request to the endpoint using your API key. Include the model ID and the input text you want the model to process.
- Receive and Use the Response: The response will include the model’s output, usage details, and other relevant information. This setup ensures you can seamlessly integrate your model into production systems.
The fine-tuned customer service model can now handle live inquiries, and you can integrate it into your support system.
Post Deployment
Monitoring and Continuous Improvement
Once deployed, use FinetuneDB’s log viewer to track production data, identify issues, and gather feedback to continuously update and improve your dataset.
Learn more about monitoring here: How to Monitor LLM Production Data
Getting Started
Fine-tuning open-source LLMs involves creating high-quality datasets, selecting appropriate models, and optimizing training settings.
FinetuneDB streamlines this process, facilitating everything from dataset creation to fine-tuning and model serving.
This end-to-end approach makes it easier for you to develop and deploy AI models that are significantly cheaper and perform better.
Ready to optimize your AI models? Reach out to FinetuneDB to evaluate your business case!
Frequently Asked Questions
What are fine-tuning datasets?
Fine-tuning datasets are curated collections of examples used to improve the performance of LLMs on specific tasks, ensuring the models understand and respond accurately to particular scenarios.
How do I create a fine-tuning dataset?
With FinetuneDB, you can create datasets by manually entering data, uploading existing JSONL files, or using production logs. The platform’s dataset manager allows easy editing and collaboration.
What are the benefits of using open-source models?
Open-source models reduce costs and offer flexibility. They can be fine-tuned to specific use cases, enhancing performance without the expense of proprietary models.
How does FinetuneDB assist in fine-tuning models?
FinetuneDB streamlines the fine-tuning process by providing tools to create and manage datasets, configure training parameters, and monitor training progress in real-time.
How do I deploy a fine-tuned model?
After fine-tuning, deploy your model using FinetuneDB’s integrated serving capabilities. This allows seamless integration and hosting, enabling real-time responses via the inference API.
How do I monitor and improve my deployed model?
Use FinetuneDB’s log viewer to track model performance, identify issues, and gather feedback. Continuously update and refine your dataset to ensure ongoing model improvement.