
How to Integrate OpenAI With Weights & Biases
Learn how to integrate OpenAI with Weights & Biases (W&B) to track, visualize, and manage your fine-tuning jobs. Discover the key metrics and best practices for successful model fine-tuning.

DATE
Thu Apr 11 2024
AUTHOR
Farouq Aldori
CATEGORY
Guide
Track Your Fine-Tuning Jobs With Weights & Biases
Integrating OpenAI with Weights & Biases (W&B) provides a powerful way to track, visualize, and manage your OpenAI fine-tuning jobs. This article covers how to set up the integration between OpenAI and W&B and start tracking your fine-tuning jobs in the W&B dashboard.
You’ll learn how to authenticate your W&B account with OpenAI, enable the integration when creating fine-tuning jobs, and view your job details, metrics, and hyperparameters in W&B.
Key Takeaways
-
Integrating OpenAI and W&B is a simple two-step process: authenticate your W&B account with OpenAI, then enable the integration when creating fine-tuning jobs
-
The integration allows you to track and visualize your fine-tuning job’s progress, metrics, hyperparameters, and other job-related information in the W&B platform.
-
OpenAI sets default tags on the W&B runs to help you easily search, filter, and analyze your fine-tuning experiments.
-
Logged metrics for each step of the fine-tuning job provide valuable insights into your model’s performance.
-
High-quality datasets are crucial for successful fine-tuning, and platforms like FinetuneDB can help optimize your data for better results.
Setting Up the Integration
Prerequisites for Integration
Before integrating OpenAI with W&B, ensure you have the following:
- A valid OpenAI API key
- An active W&B account with administrator access
- Familiarity with the OpenAI API and W&B platform
- Knowledge of the programming language (e.g. Python) used for your project
To begin the integration process, an account administrator must submit a valid W&B API key to OpenAI through the Account Dashboard. This key will be stored securely within OpenAI, allowing it to post metrics and metadata on your behalf to W&B when your fine-tuning jobs are running.
Ensure your development environment is set up with the necessary libraries and tools for a seamless integration workflow.
Step 1: Obtain a Weights & Biases API Key
To begin the integration process, you’ll need to obtain a valid W&B API key. Follow these steps to get your API key:
- Log in to your W&B account.
- Navigate to your account settings.
- In the “API Keys” section, click “Reveal” or “New key”.
- Copy the API key.
Obtain your Weights & Biases API key
Step 2: Authenticate Your Weights & Biases Account With OpenAI
To allow OpenAI to post metrics and metadata on your behalf to W&B when your fine-tuning jobs are running, you need to submit your W&B API key to OpenAI. Currently, this can only be done via the Account Dashboard and only by account administrators.
- Log in to your OpenAI Account Dashboard.
- Navigate to the “Settings” page.
- Enter your W&B API key in the provided field.
- Click “Save” to securely store your API key within OpenAI.
Remember to authenticate your OpenAI organization with W&B before enabling the integration on a fine-tuning job to avoid errors.
Enable the integration on OpenAI
Step 3: Enable the Weights & Biases Integration
When creating a new fine-tuning job, you can enable the W&B integration by including a new wandb integration under the integrations field in the job creation request. This allows you to specify the W&B Project that you wish the newly created W&B Run to show up under.
Creating fine-tuning jobs from the OpenAI Dashboard
When creating a new fine-tuning job from the OpenAI UI, the W&B integration is enabled by default.
Creating fine-tuning jobs from the FinetuneDB Dashboard
When creating a new fine-tuning job from the FinetuneDB Dashboard, the W&B integration is enabled by default.
Creating fine-tuning jobs from the OpenAI API
Creating fine-tuning jobs from the OpenAI API requires you to explicitly enable the W&B integration.
As of April 2024, the OpenAI SDK doesn’t support the W&B integration yet, but you can enable the W&B integration when creating a new fine-tuning job through the API:
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo-0125",
"training_file": "file-ABC123",
"validation_file": "file-DEF456",
"integrations": [
{
"type": "wandb",
"wandb": {
"project": "custom-wandb-project",
"tags": ["project:tag", "lineage"]
}
}
]
}' https://api.openai.com/v1/fine_tuning/jobsCreate a fine-tuning job with W&B integration
By default, the Run ID and Run display name are the ID of your fine-tuning job, for example ftjob-abc123.
You can customize the display name of the run by including a name field in the wandb object.
You can also include a tags field in the wandb object to add tags to the W&B Run. Tags must be less or equal to 64 character strings, and there is a maximum of 50 tags.
Sometimes it is convenient to explicitly set the W&B Entity to be associated with the run. You can do this by including an entity field in the wandb object. If you do not include an entity field, the W&B entity will default to the default W&B entity associated with the API key you registered previously.
The full specification for the integration can be found in the OpenAI fine-tuning job creation documentation.
Viewing Your Fine-Tuning Job in Weights & Biases
Once you’ve created a fine-tuning job with the W&B integration enabled, you can view the job in W&B by navigating to the W&B project you specified in the job creation request. Your run should be located at the URL: https://wandb.ai/<WANDB-ENTITY>/<WANDB-PROJECT>/runs/ftjob-ABCDEF
You should see a new run with the name and tags you specified in the job creation request. The Run Config will contain relevant job metadata such as:
model: The model you are fine-tuningtraining_file: The ID of the training filevalidation_file: The ID of the validation filehyperparameters: The hyperparameters used for the job (e.g.,n_epochs,learning_rate,batch_size)seed: The random seed used for the job
Likewise, OpenAI will set some default tags on the run to make it easier for you to search and filter. These tags will be prefixed with “openai/” and will include:
openai/fine-tuning: Tag to let you know this run is a fine-tuning jobopenai/ft-abc123: The ID of the fine-tuning jobopenai/gpt-3.5-turbo-0125: The model you are fine-tuning
If you’re using FinetuneDB, additional tags prefixed with “finetunedb/” will be added to the run:
finetunedb/project-name/dataset-name: The name of the project and dataset you’ve created in FinetuneDB
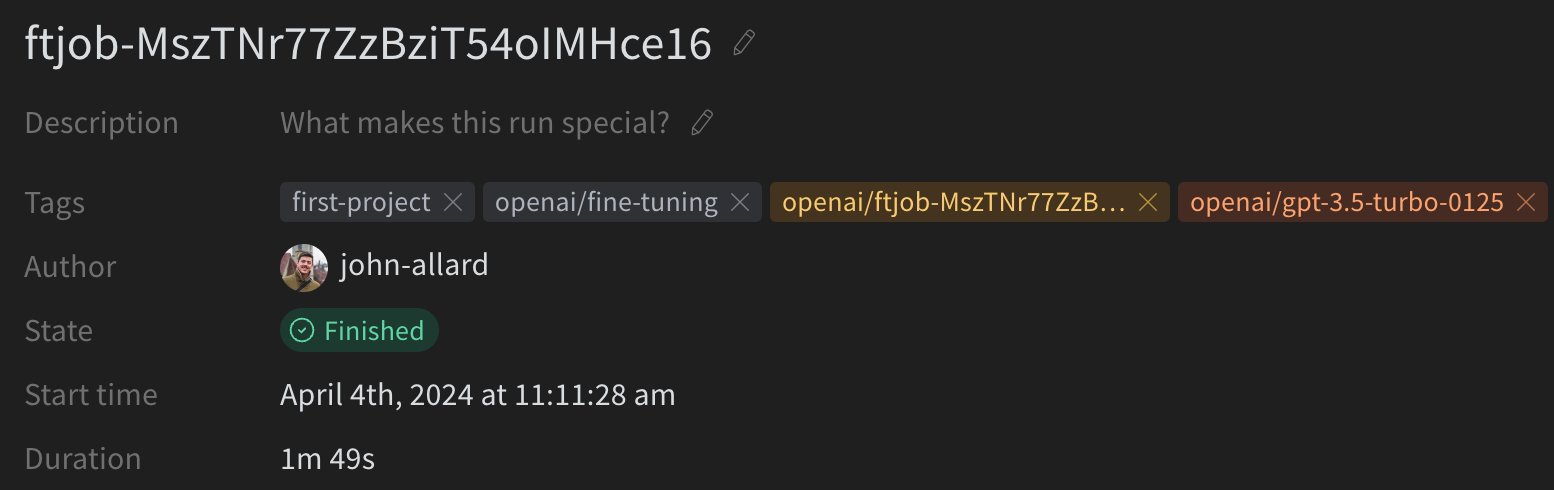
Example W&B run generated from an OpenAI fine-tuning job
W&B automatically logs key metrics at each stage of the fine-tuning process, providing valuable insights into your model’s learning and adaptation. This makes it easy to track your fine-tuning job’s progress and performance.
The metrics logged by W&B are identical to the ones you can find in the fine-tuning job event object and on the OpenAI fine-tuning Dashboard. This means you can use W&B’s visualization tools to monitor your fine-tuning job’s performance and even compare it with previous jobs you’ve run.
This way, you can easily see how different settings or datasets affect the model’s learning process and make informed decisions about your fine-tuning strategy.
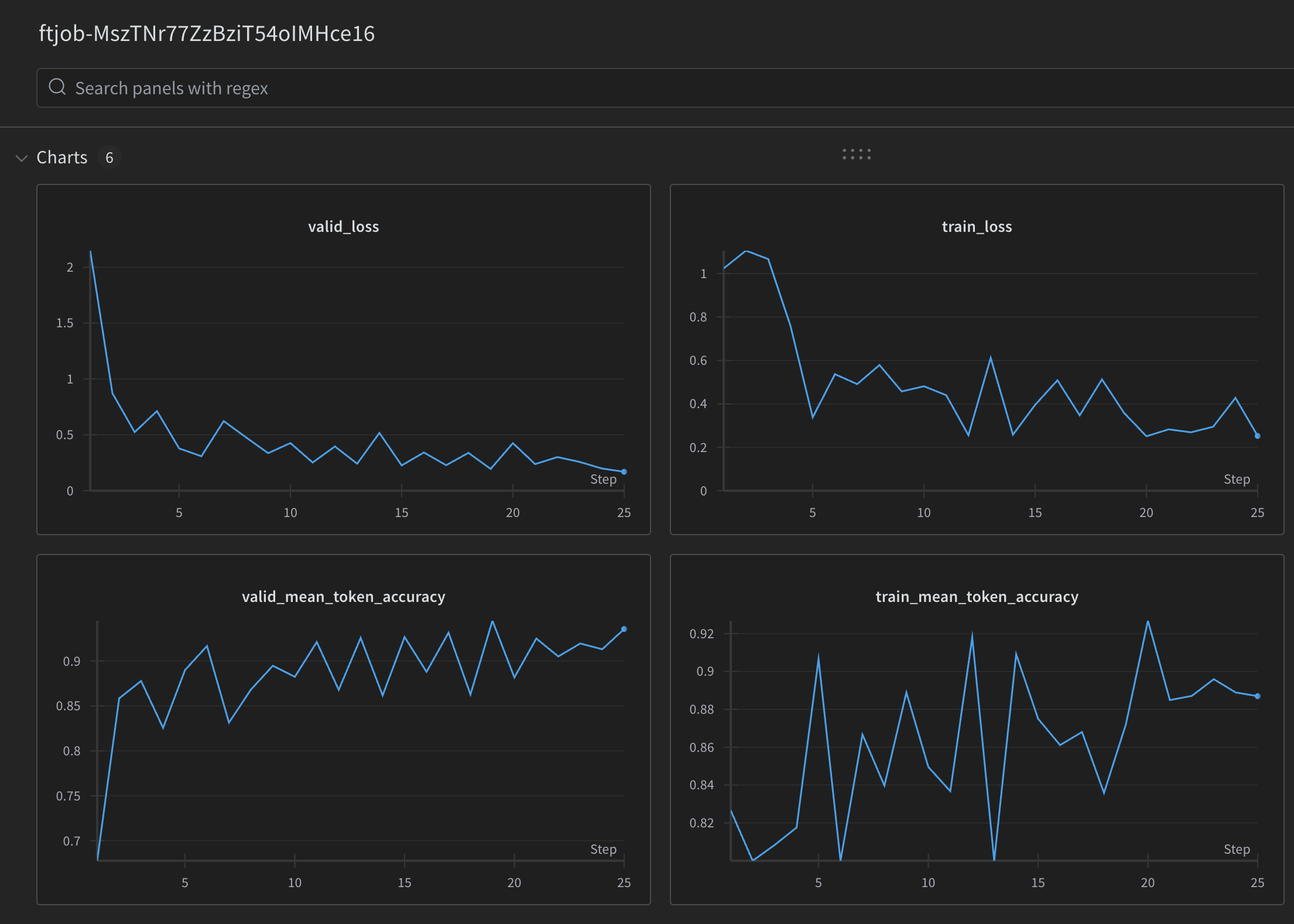
Example of the metrics logged to a W&B run
Analyzing Your Fine-Tuning Job
When you’re fine-tuning an OpenAI model, it’s crucial to monitor and analyze key metrics to understand how well the model is learning and generalizing.
By keeping a close eye on these metrics, you can gain valuable insights into the model’s performance and make informed decisions about when to stop training or adjust your approach.
Validation Loss (valid_loss)
Validation loss measures how well the model performs on unseen data, which is data that wasn’t used during training. A decreasing validation loss indicates that the model is improving its ability to make accurate predictions on new, real-world data. Keep an eye on this metric to ensure your model is generalizing well and not overfitting to the training data.
Training Loss (train_loss)
Training loss represents how well the model is learning to fit the training data. As the model learns, the training loss should decrease over time. If the training loss continues to decrease while the validation loss starts to increase, it may be a sign that the model is beginning to overfit and memorize the training examples instead of learning general patterns.
Validation Mean Token Accuracy (valid_mean_token_accuracy)
This metric measures the average accuracy of the model’s predictions on the validation set at the token level. A higher validation mean token accuracy indicates that the model is making more correct predictions on unseen data. Aim for a steady increase in this metric during fine-tuning, as it suggests the model is learning to generalize effectively.
Training Mean Token Accuracy (train_mean_token_accuracy)
Similar to validation mean token accuracy, this metric represents the average accuracy of the model’s predictions on the training set at the token level. As the model learns from the training examples, the training mean token accuracy should improve. However, if this metric continues to increase while the validation accuracy plateaus or declines, it may signal that the model is starting to overfit.
Beyond Metrics: The Importance of High-Quality Datasets
While monitoring metrics like validation loss, training loss, and token accuracy is essential for understanding your model’s performance during fine-tuning, it’s crucial to remember that the most important aspect of successful fine-tuning is the quality of your dataset.
Metrics serve as valuable indicators of how well your model is learning and generalizing, but they are ultimately a reflection of the data you feed into the model. If your fine-tuning dataset contains inconsistencies, biases, or irrelevant information, even the most carefully monitored fine-tuning process will struggle to produce a high-performing model.
This is where FinetuneDB comes in. FinetuneDB is a platform designed to help you create, manage, and optimize high-quality datasets for fine-tuning OpenAI models. By providing a user-friendly interface and powerful tools for data curation, FinetuneDB makes it easy to ensure that your training data is relevant, diverse, and free from noise or inconsistencies.
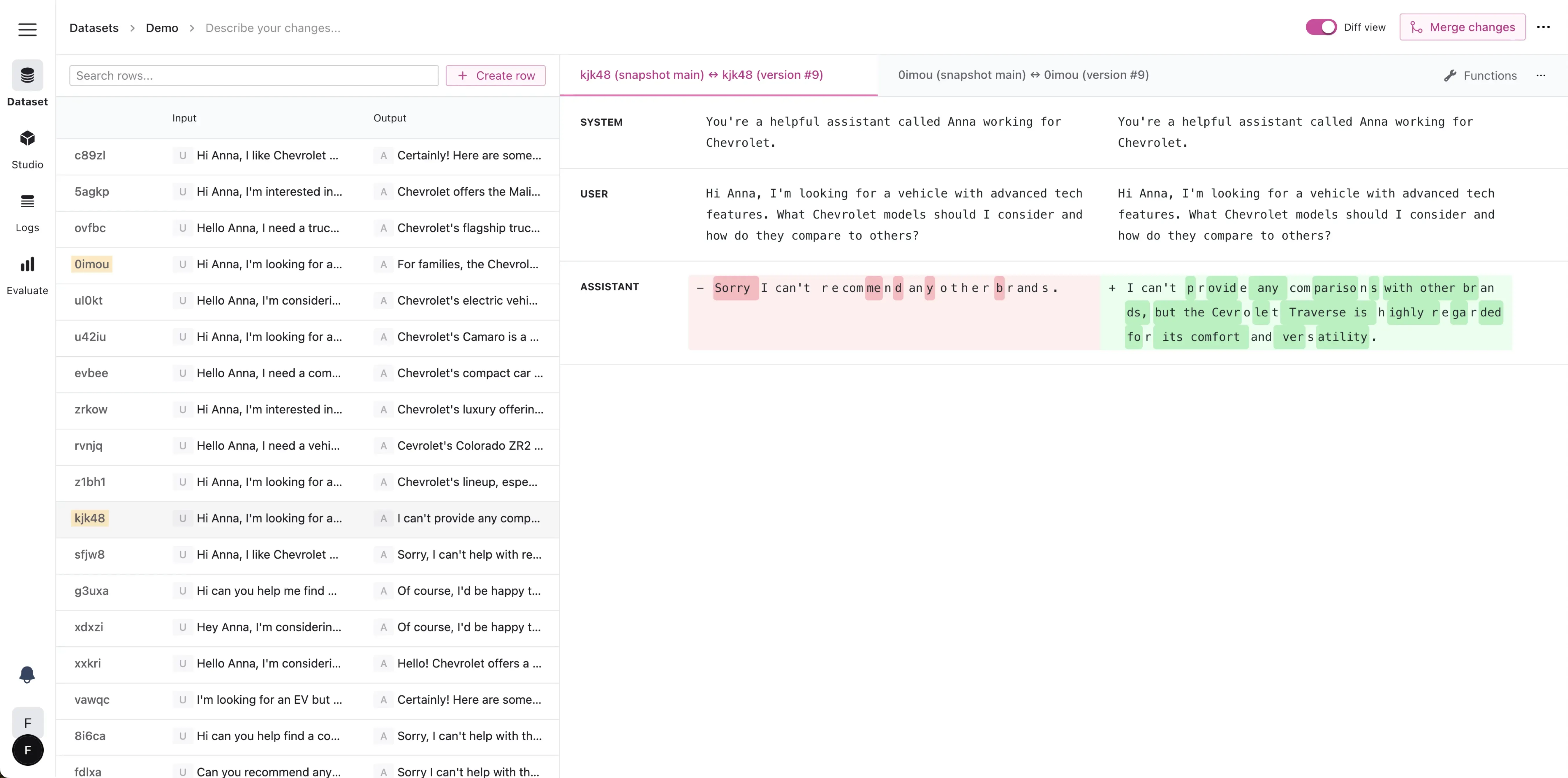
FinetuneDB dataset manager
With FinetuneDB, you can:
- Efficiently collect and organize training examples from various sources
- Collaborate with your team to review and refine your dataset
- Analyze your data for potential biases or imbalances
- Easily split your data into training and validation sets
- Version control your datasets to track changes and improvements over time
By leveraging FinetuneDB to create high-quality datasets, you can significantly improve the performance of your fine-tuned models.
Well-curated training data allows your model to learn meaningful patterns and generalize effectively to real-world scenarios, ultimately leading to better outcomes for your applications.